
近日, 在浏览伯乐在线的时候碰到一些很不错的资源: 25本免费的Python电子书
如下图:

其中,每本都是以名字+超链接的方式,于是激起了我写个小程序保存这些资源的欲望,顺便也能练习一些不太熟练的小爬虫 : ) 。 好了,我们开始吧!
先展示一下成果给大家看嗯: 如图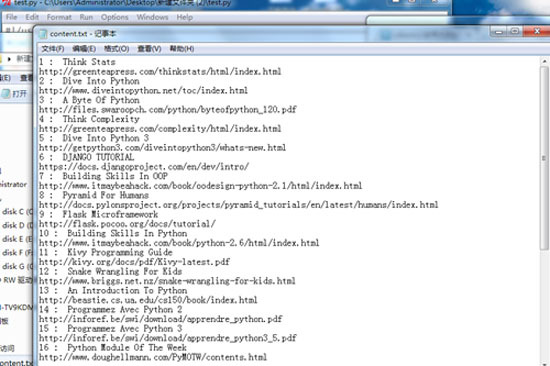
每本书都很有条理的保存在本地文档中,结果还是挺满意的哈。
首先呢 要完成这些工作大概要分为一下几个步骤:
获得整个页面的源代码 (网页源码HTML)
获得目标区域的源代码 (缩小范围)
在小范围内匹配资源的URL
将匹配到的资源URL写入到本地保存
下面,将分为4个步骤来分部展示Python程序
第一, 获得整个页面的源代码:
1 | def getHtml(url): |
该段代码将返回资源所在的整个页面的HTML源代码
第二,获得目标区域的源代码 (缩小范围):
1 | def getRange(content): |
第三,匹配资源的URL:
1 | def getLink(content2): |
以上俩个函数分别用来匹配资源的 链接 和 书名
第四,保存到本地:
即是在print 的基础上从定向到文件中。详见下面的完整代码 : )
下面是完整代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40#!/usr/bin/env python
#coding:utf-8
import urllib
import re
def getHtml(url):
html = urllib.urlopen(url)
sorce = html.read()
return sorce
def getRange(content):
start0 = content.find(r'<div class="entry">')
start = content.find(r'<ol>',start0)
end = content.find(r'<div id="ad1">',start)
content2 = content[start:end]
return content2
def getLink(content2):
reg = re.compile(r'<a href="(.*?[.html|.pdf]?)" target=')
result = reg.findall(content2)
return result
def getName(content2):
reg = re.compile(r'<a href=".*?[.html|.pdf]?" target="_blank">(.*?)</a>')
result2 = reg.findall(content2)
return result2
if __name__ == '__main__':
content = getHtml(r'http://blog.jobbole.com/29281/')
content2 = getRange(content)
link = getLink(content2)
name = getName(content2)
i = 1
f = open('content.txt','w+')
for x, y in zip(name, link):
print >>f, str(i),": ",x,
print >>f
print >>f,y
i = i + 1
看到这里您辛苦了,谢谢 : )
—————————————————————————————————————————————————————————————————————————————
声明:
本文为博主对自己所学的知识整理和实现。
本文档欢迎自由转载,但请务必保持本文档完整或注明来之本文档。本文档未经本人同意,不得用于商业用途。最后,如果您能从这个简单文档里获得些许帮助,我将对自己的一点努力感到非常高兴;由于本人水平有限,如果本文档中包含的错误给您造成了不便,在此提前说声抱歉。
祝身体健康,工作顺利。