
本篇作为Scrapy爬虫的第一篇, 引用的是Scrapy官方的例子, 目标读者是听说过Scrapy这个爬虫框架, 但是还没有自己使用过, 主要介绍Scrapy最基本的知识, 没有其他新颖的东西, 看过官方文档的人可以选择略过 : )
首先默认大家都已经安装过了Scrapy了, 没有安装的人请执行pip install scrapy进行安装, 若遇到问题, 请自行谷歌(百度)解决。
1. 新建一个Scrapy工程
在终端下(Windows下叫命令行)1
scrapy startproject stack
这样一个工程便建成功了, 这时, 你会在当前目录下发现一个叫做stack的文件夹, 这便是Scrapy为我们生产的工程目录。
其结构如下图所示
其中比较重要的几个文件是items.py, pipelines.py, settings.py, 自定义的爬虫文件
下面分别介绍这四个文件:
- items.py : 该文件中存储我们将要提取的数据(类似于MVC架构中的Model)。
- pipelines.py : 该文件俗称”管道“, 顾名思义, 用来处理我们提取到的数据(去重, 验证, 存储到数据库)。
- settings.py : 配置文件, 该文件定义一些常见的配置参数。
- 自定义的爬虫文件 : 主要的爬虫逻辑在该文件实现, 默认没有生成, 需手动自己创建。
2. 定义我们的Item
1 | from scrapy import Item, Field |
即: 我们感兴趣的数据是标题和标题的URL地址
3. 编写我们的爬虫文件
在spiders文件夹下新建stack_spider(名字随意, 不过不能叫stack会让程序混淆工程根目录和爬虫文件)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath('a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath('a[@class="question-hyperlink"]/@href').extract()[0]
yield item
在我们的StackSpider爬虫类中主要有name, allowed_domains, start_urls这三个重要的属性
- name : 爬虫名字, 后面启动爬虫时要用到
- allowed_domains : 指定爬虫爬取的域名
- start_urls : 一个列表属性, 爬虫程序开始时候循环遍历其中的url进行处理
最后因为我们这个StackSpider继承了Spider类, 所以其中要实现parse方法, 默认程序启动后每遍历一个url便将响应结果交给parse方法来处理, 所以我们必须要在parse中实现自己的抓取逻辑
这里要介绍Scrapy里两个重要的概念Selector(选择器)和XPath
Selector是Scrapy中提取数据的一套机制, 通常配合XPath和CSS来“选择”HTML文件中的某个部分。XPath是一门用来在XML文件中选择节点的语言, 也可以用在HTML上。CSS是一门将HTML文档样式化的语言。选择器由它定义, 并与特定的HTML元素的样式相关联。
4. 编写通道(pipelines.py)文件
1 | import pymongo |
如上所示, 这个MongoDBPipeline主要的工作就是讲采集到的数据保存到mongo数据库中, 在__init__中负责连接mongo, 其中的配置见一下个小标题, 而process_item是每个Pipeline都默认必须要实现的方法, 用来对数据具体处理。
5. 编写配置文件(settings.py)
1 | BOT_NAME = 'stack' |
配置文件主要是配置各个Pipeline的优先级, 数字越小, 优先级越高。 并配置mongo的一些参数server, port, db, collection。
6. 结果
编写完成后, 回到工程根目录下执行以下命令1
scrapy crawl stack -o data.json
之后便可在mongodb数据库和data.json文件中看到抓取下来的数据。
mongo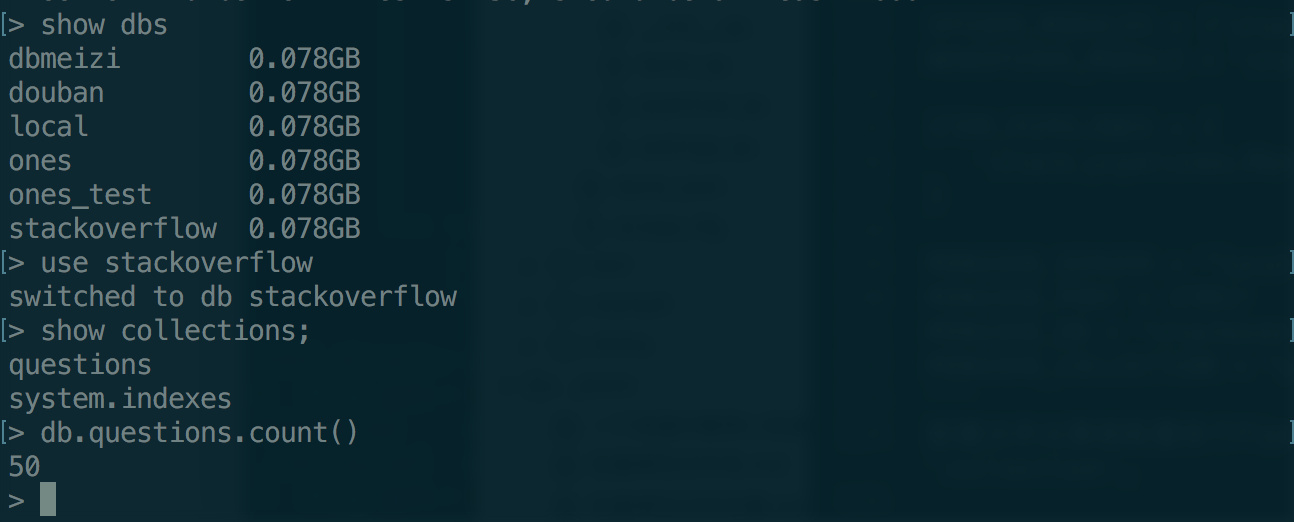
mongodb的简单使用方法可以参考我的另外一篇笔记。
data.json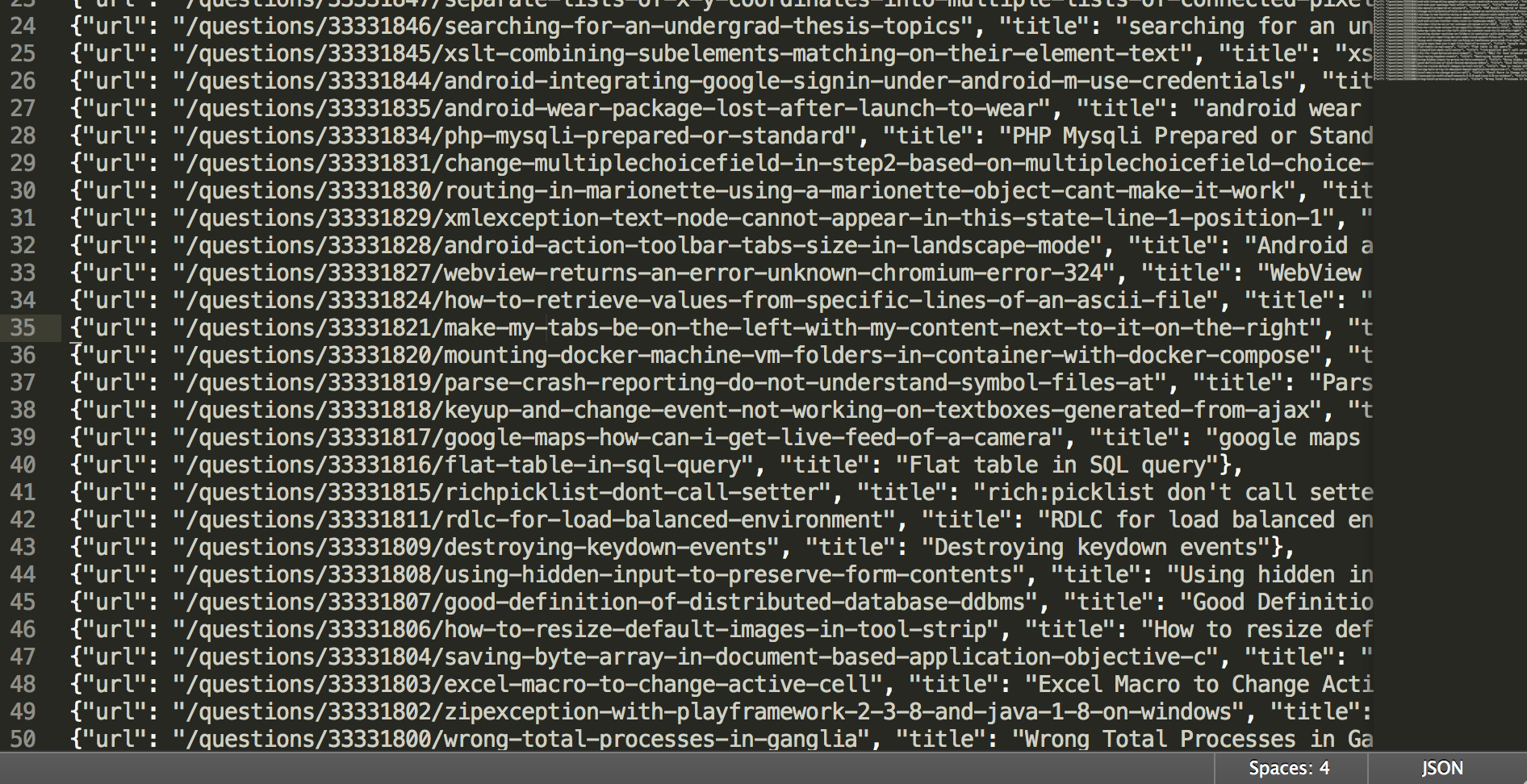
(完)