
本节是Scrapy系列中的一节, 主要是多页面, 多Item和 图片下载功能的爬取。
本次我们要爬取的站是我个人非常喜欢的一个站点, 即韩寒的一个, 每天会更新一张图片, 一句话, 一篇文章和一个问答, 页面十分简洁。如下图所示:



1. 定义爬虫内容 item.py
首先定义我们感兴趣的内容, 按照 photo, article, ask 分别爬取。
1 | # -*- coding: utf-8 -*- |
2. Spider的编写
定义好了 Item, 那么接下来就是我们的 Spider了, 整个逻辑非常简单, 首先解析每天的页面(主页面), 再由主页面分别获得 photo, article 和 ask的链接, 再发起请求来获得分别的详情页面。
1 | # coding: utf-8 |
3. 数据处理 pipeline.py
这里我们主要有三个Pipeline, 其中一个是 Scrapy 自带的下来图片的 Pipeline, 还有两个分别是处理爬取到的item中时间格式的和将输入存入 mongo 数据库的 Pipeline。
1 | # -*- coding: utf-8 -*- |
4. 配置文件 settings.py
最后, 我们需要在 setting 中做以下配置, mongodb的数据库等信息, 图片下载保存地址 和 Pipeline 优先级
添加以下设置到settting.py
1 | MONGODB_SERVER = "localhost" |
5. 效果展示
最后在工程目录下执行命令
scrapy crawl ones
大约等待一个小时左右, 整个站的数据应该都被爬取完成咯。数据量大概是 photo, article, ask各有1350个左右。
如下图:
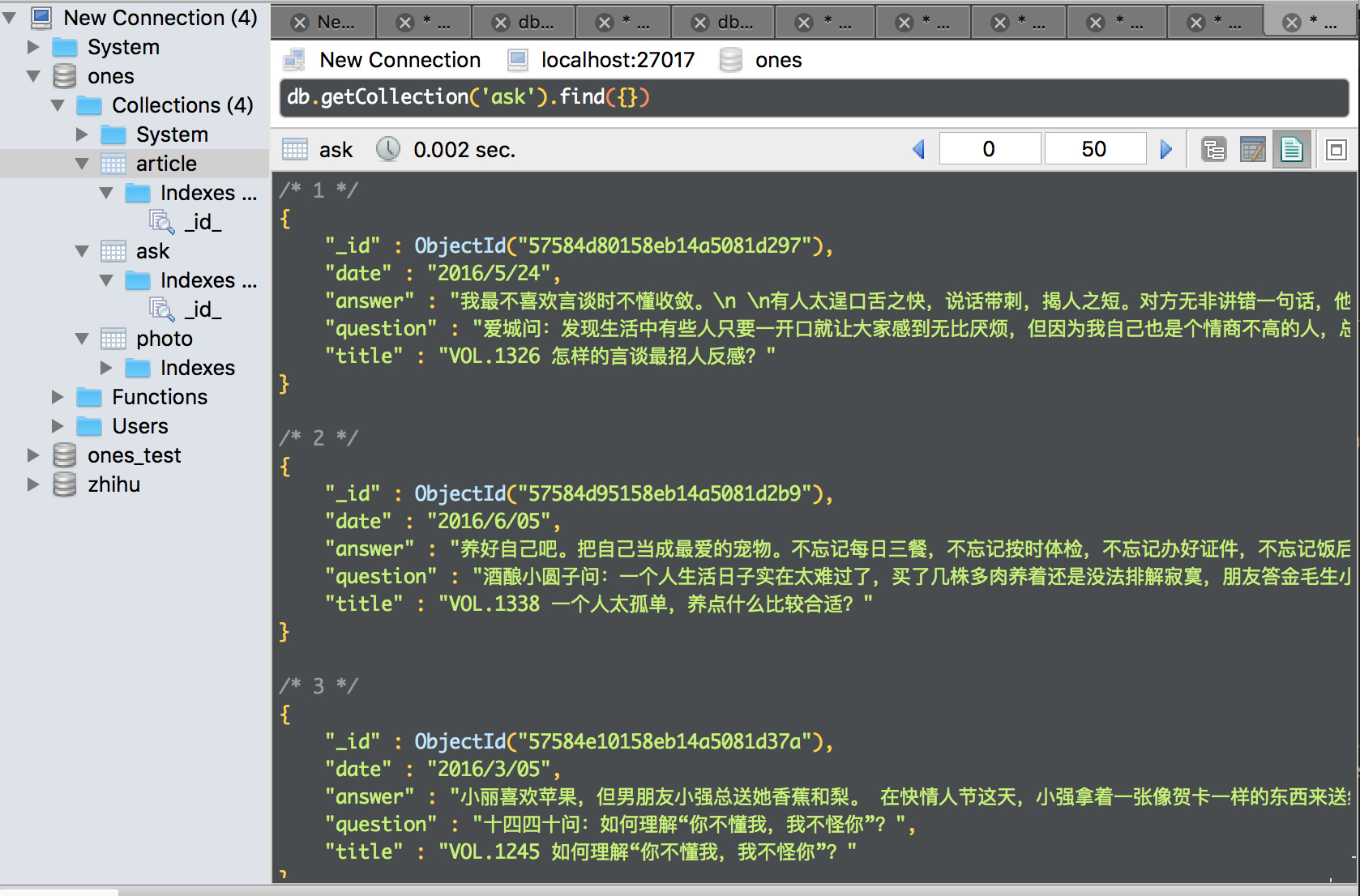
同时下载的图片(妈妈再也不怕我找不到精美图片了)
项目代码, 点我下载。
以上, 欢迎食用~ , 觉得有收获, 留个言给点鼓励嘛!!! ᕙ(⇀‸↼‵‵)ᕗ