
1. item.py(定义爬去的内容)
1 | import scrapy |
2. spider 的编写
1 | from scrapy.spiders import CrawlSpider, Rule |
3. PipeLine 中处理数据及图片下载
1 |
|
4. setting 中设置几个变量
1 |
|
5. 结果
写好后保存然后在目录下运行 scrapy crawl movies -o data.json 等待一会, 即可在目录下看到 data.json 文件如下:
和 封面图片都被下载下来咯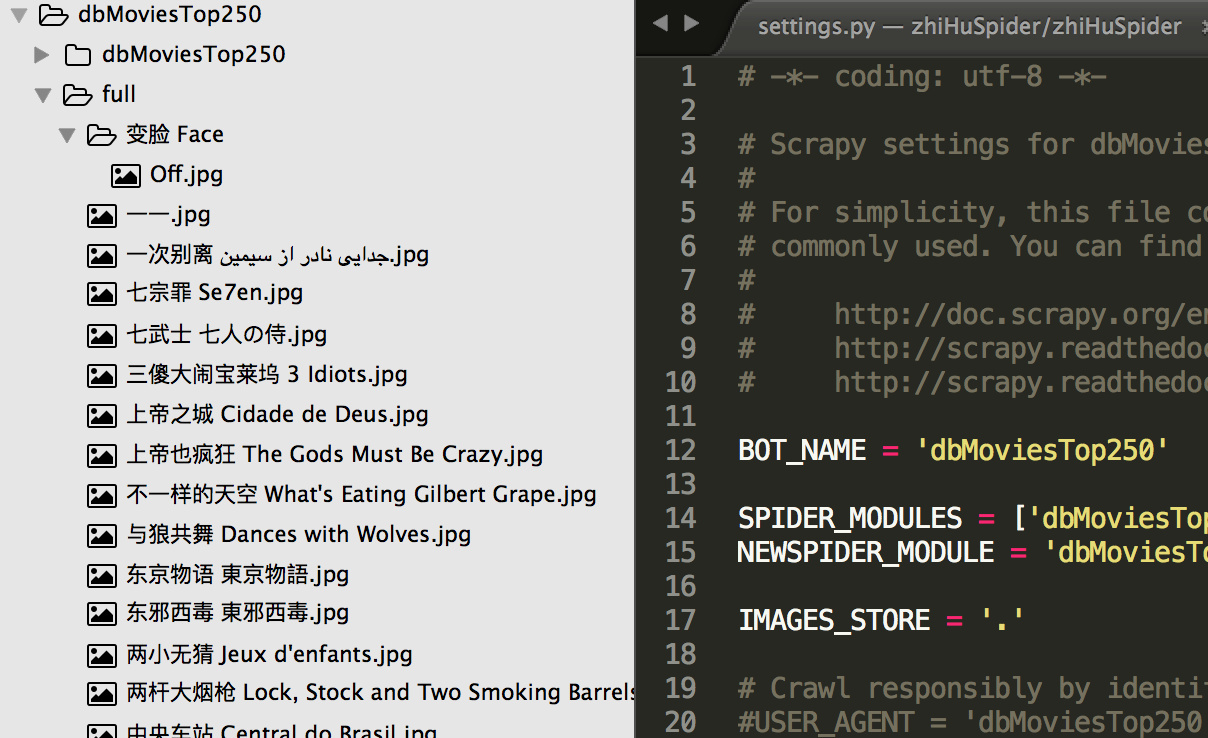
项目代码, 点我下载。
这样Top250电影的相关信息就被我们拿到啦。 赶快试试吧!!!